First steps in Meta Learning
Data
The key idea I needed to get my head around when first encountering meta learning was how data was handled. The data is split as usual into train, val, test but the split is across classes rather than across examples.
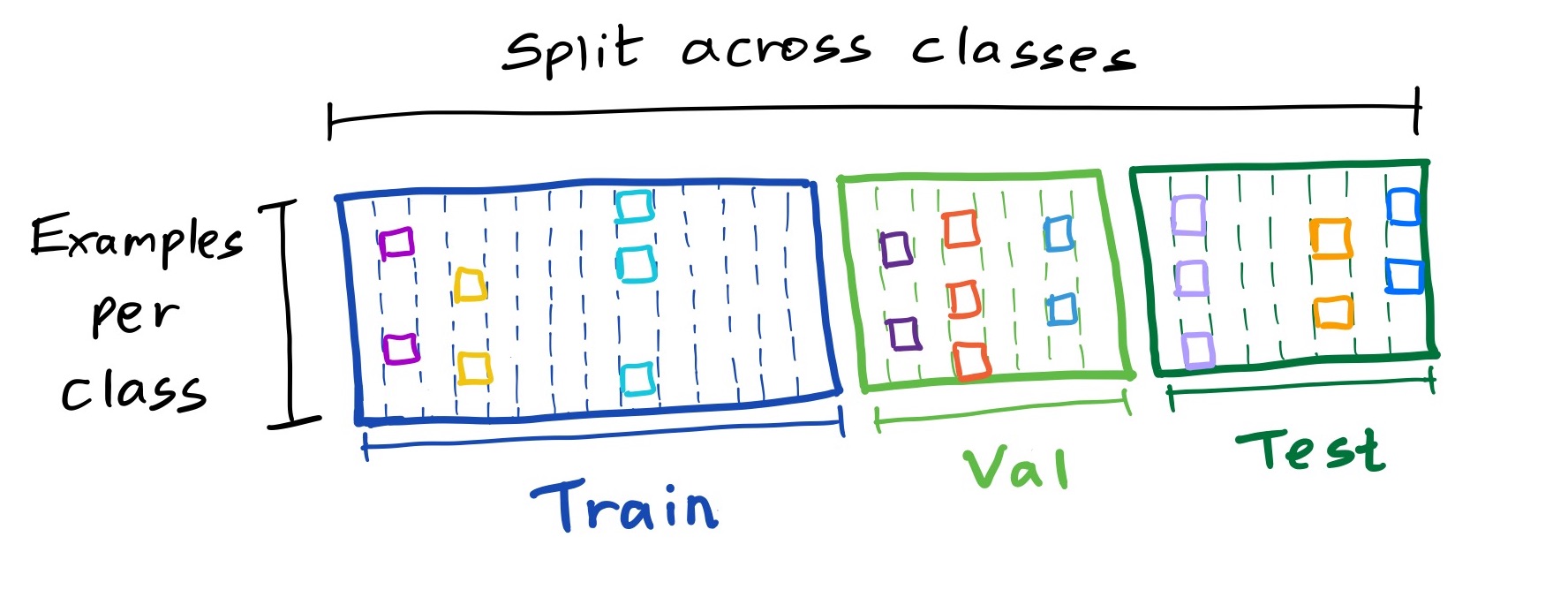
An input is a sequence of data points from a few classes. Mini-distributions are created by sampling subsets of $N$ classes from a larger dataset. These mini training sets typically consist of just one or a very few examples per class hence one / few shot learning. The classes in the sample are arbitrarily assigned e.g. from $0 … N-1$ without regard to the classes in the original dataset.

Each input is not considered a sample from a distribution over data points but a sample from a distribution of training sets or “tasks”. A task does not need to be what we normally consider a task but it usually describes problems are in some way different from each other but also share some structure.
For example we might normally train models for them independently but use similar kinds of models. The mini training sets described above represent tasks that all involve the same problem (such as image classification in the SNAIL model discussed below) but what makes them “tasks” is that they are treated like separate datasets each of which may have kinds of data not present in others.
A certain number of the elements of the sequence are the “training” examples of this mini training set and the rest are ”test” examples.
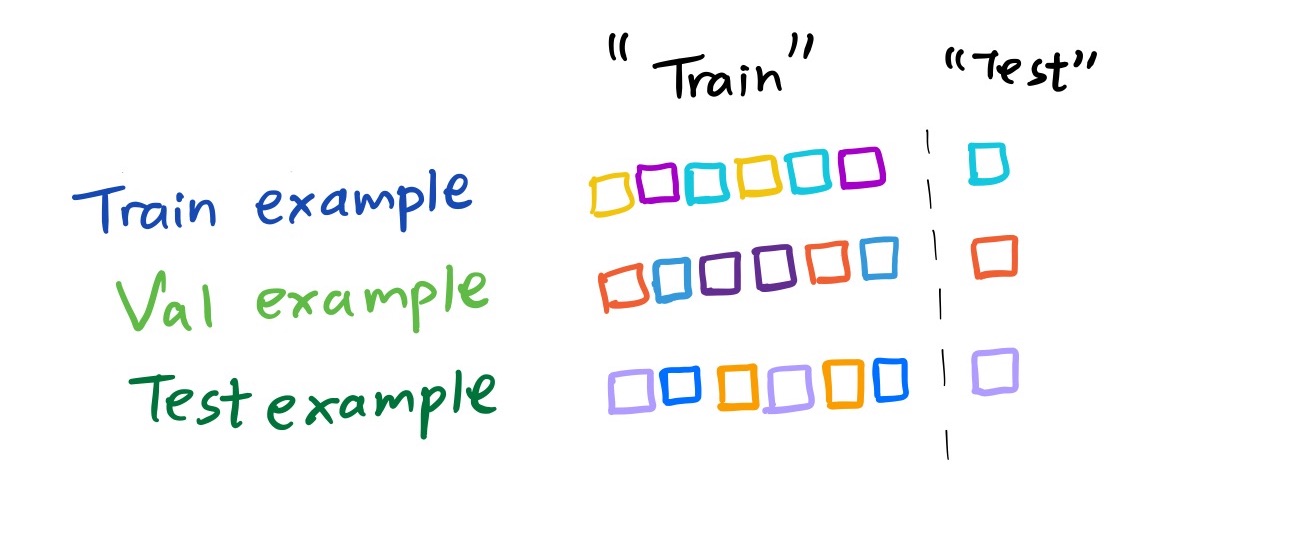
The model is fed pairs of data points and labels from the training elements of the mini-distribution and learns to predict the class of the test elements of this mini-distribution. The model is evaluated based on how well it can learn a task after seeing just a few datapoint, label pairs. At evaluation time, the model is fed inputs in a similar way and evaluated based on its prediction of the test elements of the sequence.
Model
I have been following the curriculum of Stanford Deep Multi-Task and Meta Learning and the first homework assignment involves rather very simple architecture so I decided to implement the SNAIL model instead, which is a transformer-style attention based sequence model.
(From Figure 1 of [1])
I found it rather a painful process to implement SNAIL and even now I am not entirely satisfied with the results. The paper provides full details about the model architectures used including pseudo-code but remarkably little information, at least for the image classification experiments, about training such as the number of episodes, batch size, number of samples used for evaluation, etc.
CS330 homework 1 had some instructions and starter code that helped me to some extent and I also came across this PyTorch on Github which was helpful although I didn’t want to ‘cheat’ by referring to it too much.
You can find a Colab notebook with my implementation here but use at your own risk. So far I have run experiments only for the 1-shot 5-way setting and although the results are reasonable (~98.7% test accuracy compared to the reported 99.07% $\pm$ 0.16%), I have not checked them carefully.
References
[1] Stanford Deep Multi-Task and Meta Learning
[2] SNAIL